고위합성 튜토리얼(High-Level Synthesis Tutorial)
High-Level Synthesis(HLS)을 일본에서 '고위합성'이라고 했던데 의미가 와닿게 옮겼다는 생각이다. [High Level Synthesis Blue Book 일본어판] 높은 추상화 수준으로 기술된 설계를 논리회로 하드웨어로 합성 해주는 기법 이다. 영어로는 C-Based design methodology, transforming C, C++, and SystemC code into Register Transfer Level (RTL) code for synthesis. 지난 시절 한때는 모질게 메달렸던 분야 였지만 떠난지 십년은 된 듯하다. 지금와서 다시 꺼내 보는 이유는 다 잊어 버리기 전에 정리해 두고 싶었기 때문이다. 변변한 HLS 툴 도 없어서(사실은 어마어마한 가격을 지불할 돈이 없었다.) 상상으로 공부하던 시절에 비하면 이 얼마나 감격인가 싶어서 20년전의 한을 풀어보고자 한다. 이 글을 쓰는 시점에서 몇주전(2021년 7월) 지멘스사의 C기반 설계 및 검증에 관한 온라인 세미나를 보게 됐었다. 여전히 C 언어 기반의 설계를 홍보하고 있는 걸 보며 감개무량 했다. 20년이 지났지만 아직도 할말이(잘난척 할 수) 있다니....
안타깝게도 C/C++가 반도체 설계자들 사이에 여전히 인기가 없다 보니 널리 쓰이는 것 같지 않다. 2004년 SNUG에서 발표한 스튜어트 서덜랜드의 논문 'Integrating SystemC Models with Verilog and SystemVerilog Models Using the SystemVerilog Direct Programming Interface' (이 논문을 기억하는 이유는 참고문헌에 내가 언급되었기 때문임)에서 HDL 기술자에게 C++는 겁먹게 하는 대상이라고 언급 되었는데 지금도 그런지는 모르겠다. 가르치는 교육기관(대학이나 학원)이 있는지도 모르겠고....
마침 자일링스에서 HLS를 연습해 볼수 있는 좋은 교재가 있길래 이를 따라가 보기로 한다.
Vivado Design Suite Tutorial High-Level Synthesis UG871 (v2020.1) August 7, 2020
PDF / Design Files
몇가지 실습을 따라해본 소감은 대단한 발전이라는 생각이 들었다. 다만 검증 도구가 문제였다. C++나 Verilog, VHDL 같은 HDL도 모두 구문 규칙이 강직한 컴퓨팅 언어이므로 자동화된 변환이 가능 하겠지만, 검증은 말 그대로 고도의 작업이다. 설계물의 검증을 위해 시험 환경을 만들어 주어야 한다. 과연 이 시험 환경에 결함이나 헛점이 없길 바란다. 소프트웨어의 개발에서도 검증에 많은 투자를 한다. 하드웨어 개발시 검증은 전체 개발비(+시간)의 8할 이상이라고 한다. C언어로 기술된 것을 합성하여 얻은 RTL 설계물 역시 검증되어야 한다.

자일링스 HLS 도구에 C 로 작성된 검증 코드를 RTL 테스트벤치로 변환해 주는 도구도 포함되어 있다. C의 main() 을 읽어서 HDL 테스트 벤치를 생성해 주다니 감동적이다. 그들은 Co-Simulation이라고 자랑했다. 처음은 감동 이었다. 그런데 ......

구문해석기(apcc 라고한다)를 이용해 C 테스트 코드를 분석하여 설계물과 시험 환경 사이에 주고 받는 자료를 파일로 저장하는 부분이 삽입된 또다른 C를 생성하는 것이었다. 이렇게 생성된 C를 GCC로 컴피일 하여 실행시키면 테스트 결과 파일이 만들어 질테고 결국 diff 유틸리티로 입출력 벡터 파일을 비교해 보는 것으로 검증을 마친다. 변환된 테스트 벤치의 무결성을 보장받기 위해 자동화된 툴 체인을 갖춘점은 칭송할 만 하지만 Co-Simulation이라기엔 부족했다.

제대로 된 Co-Simulation 이라면 이래야 하지 않을까?
- 설계물의 C 코드에 변경 없을 것
- RTL 테스트 벤치에 실행형 바이너리로 결합될 것(Executable specification)
- 시뮬레이션 실행 중 실시간으로 입출력 검증이 이뤄질 것
이미 HDL과 C++를 동일한 환경에서 실행이 가능한 도구(C-HDL Mixed simulation)가 준비되어 있다. HDL에서 C 언어 인터페이스를 위해 Verilog의 PLI와 VPI, VHDL의 FLI와 VHPI, SystemVerilog 의 DPI 등이 표준화 되어있다. 하지만 이런 인테페이스 기준은 지나치게 복잡해서 학습 접근을 막고(반도체 하드웨어 설계자에겐 C++는 여전히 높은 벽인가?) 때로는 설계물의 C 코드를 변경을 요구하기도 한다. 게다가 HDL 전용 시뮬레이터가 아니면 실행 시킬 수 없다. 다행히 SystemC가 IEEE 1066-2011으로 표준 제정되다. SystemC는 C++를 라이브러리 수준에서 확장한 것이므로 GCC 나 비주얼 C++ 같은 표준 C++ 컴파일러 라면 실행 파일 생성이 가능하다.
어쨌든 자일링스 HLS 도구는 인상적이다. 그들이 제공한 튜토리얼을 따라가 보고 SystemC 로 Co-Simulation을 구성해 본다.
[참고]
[1] High Level Synthesis Blue Book
[2] 'Integrating SystemC Models with Verilog and SystemVerilog Models Using the SystemVerilog Direct Programming Interface
[3] 시스템수준 언어: SystemC & SystemVerilog
[4] Vivado Design Suite Tutorial High-Level Synthesis UG871
[5] 머신러닝(ML) 구현에서 ‘상위수준합성(High Level Synthesis, HLS)’이 주목받는 이유
[6] ESL 기반 설계 및 HLS 최신 동향 분석
[7] SystemC Verification with ModelSim
[8] AI/ML Accelerator Tutorial/C-Based Design & Verification
[9] Vivado Design Suite User Guide:High-Level Synthesis UG902 (v2021.1) May,4
[10] UltraFast Vivado HLS Methodology Guide UG1197 (v2020.1) June 3, 2020
[11] Vivado Design Suite Tutorial High-Level Synthesis UG871 (v2020.1) August 7, 2020, PDF / Design Files
------------------------------------------------------------------------------
목차 Table of Contents
1장: 튜토리얼 개요 (Tutorial Description)
2장: 고위합성 맛보기(High-Level Synthesis Introduction)
실습 1: 고위합성 프로젝트
단계 1: HLS 프로젝트 생성 (Create HLS Project)
단계 2: C 소스코드 검증 (Validate the C Source Code)
단계 3: 고위합성 (High-Level Synthesis)
단계 4: RTL 검증 (RTL Verification)
단계 5: IP 제작 (IP Creation)
요약: 자일링스 HLS 도구 의 흐름(Tool Flow)
추가: SystemC Co-Simulation Testbench
실습 2: Tcl 스크립트(Tcl Scripts)
실습 3: 설계 최적화(Design Optimization)
3장: C 설계의 바름 검증(C Validation)
개요
실습 폴터구조
실습 1. GNUPLOT 를 이용한 도식화
실습 2: GNUPLOT, Windows GDI+, SDL Lib 그리고 Python을 내장한 SystemC 테스트 벤치
2-1. sc_fifo<T> 채널을 이용한 시스템 수준(System Level) 테스트 벤치
2-2. sc_signal<T*>
2-3. sc_signal<T>, 클럭 상세(clock-level data transfer) 데이터 전송
실습 3. Arbitrary Precision Type
4장: 인터페이스 합성(Interface Synthesis)
개요
실습 1. 블럭 수준 입출력 프로토콜(Block-Level I/O Protocol)
실습 2. 포트의 입출력 핸드쉐이크 프로토콜(Port I/O Protocol)
실습 3. 배열로 주어진 인수의 RTL/FIFO 인터페이스 구현(Implementing Array as RTL/FIFO Interface)
3-1. 메모리 인터페이스 합성
3-2. FIFO 인터페이스 합성
3-3. 핸드쉐이크 없는 함수의 호출과 종료
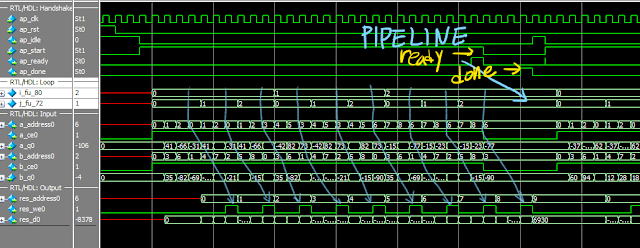
3-4. 중단없는 파이프라인
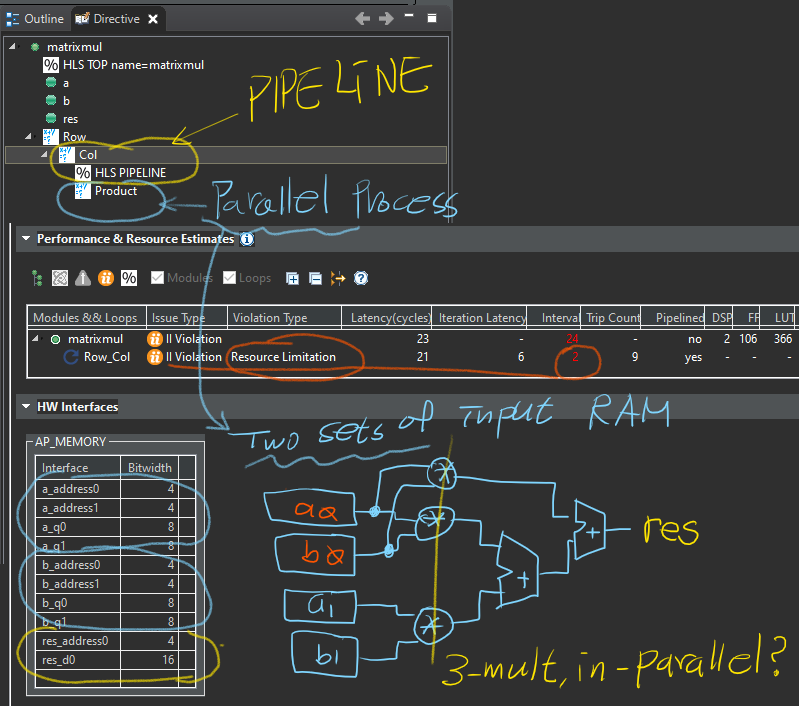
3-5. 내부구조 선택: 파이프라인 구조 vs 병렬 구조
실습 4. AXI4 인터페이스(Implementing AXI4 Interfaces)
5장: 임의 정밀도 형(Arbitrary Precision Type)
개요
C++의 템플릿(template)
실습 1. 부동소숫점 자료형으로 합성
실습 2: 임의 정밀도 자료형으로 합성
6장. 설계 분석 (Design Analysis)
개요
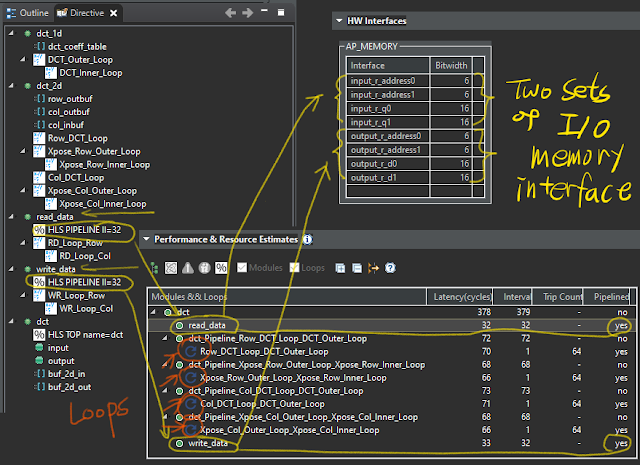
C 설계 검토 및 검증: 2차원 DCT(2-D Discrete Cosine Transform)
단계 1. 최초 합성
단계 2. 최상위 모듈에 파이프라인 지시(최고 클럭 성능)
단계 3. 최상위 모듈에 파이프라인 억제 지시(최소 하드웨어 자원)
단계 4. 반복문 최적화: 파이프라인 지시 및 메모리 분할
단계 5. 병렬성 강화 최적화 (DATAFLOW)
단계 6. 계층구조 최적화 (INLINE)
7장. 설계 최적화(Design Optimization)
개요
실습 1: HLS 지시자의 적용에 따른 합성 결과 분석
단계 1. 병렬처리가 억제된 합성(최소 하드웨어)
단계 2. 최하위 반복에 파이프라인 지시
단계 3. 상위 반복에 파이프라인 지시
단계 4. 배열 재정렬(ARRAY_RESHAPE)
단계 5. FIFO 인터페이스
단계 6. 함수 전체에 파이프라인 지시
실습 2: 소스 코드 변경