7장. 설계 최적화 (Design Optimization)
실습 1: HLS 지시자의 적용에 따른 합성 결과 분석
단계 1. 병렬처리가 억제된 합성(최소 하드웨어)
단계 2. 최하위 반복에 파이프라인 지시
단계 3. 상위 반복에 파이프라인 지시
단계 4. 배열 재정렬(ARRAY_RESHAPE)
단계 5. FIFO 인터페이스
단계 6. 함수 전체에 파이프라인 지시
실습 2: 소스 코드 변경
[소스다운로드]
----------------------------------------------------------------------------------------------------
개요
C 코드에 적절한 합성 지시자를 적용하여 최적 성능의 RTL/HDL을 얻는 것이 고위 합성(HLS)의 목표다. 최적성능은 속도(인터벌 클럭 소요 갯수)와 하드웨어 사용량으로 평가된다. 고위 합성기는 먼저 반복문 또는 함수의 작동을 완료하는데 소요되는 클럭 수, 즉 레이턴시를 최소화하는데 총력을 기울인다. 이를 위해 실행문들 사이에 변수들의 의존 관계를 따져 병렬 실행이 가능하도록 분리해내고 의존 관계가 존재하는 경우 파이프라인 처리 구조를 찾는다.
C로 기술된 알고리즘에서 병렬성과 파이프라인 구조가 항상 선명하게 드러나는 것은 아니므로 구조를 파악하여 적절한 지시자를 주어야 한다.
- 병렬성(parallelism): 병렬처리가 많아 질수록 하드웨어의 규모는 기하급수적으로 늘어나지만 HLS의 근본 목적이 속도 성능을 높이는 것이므로 최대한 병렬성을 추구한다. 따라서 가장 먼저 병렬성을 찾기 위해 실행문에서 의존관계를 따진다. 많은 연산이 포함된 알고리즘 일수록 배열 변수를 활용하게 되는데, 이 배열 변수들은 메모리로 구현하여 하드웨어 용량을 절약 한다. 하지만 다수의 값을 동시에 불러오지 못하는 메모리는 병렬처리를 저해하는 요소가 될 것이다.
- 파이프라인(pipeline): 실행문 사이의 의존 관계가 있는 경우 파이프라인 구조를 취하여 클럭당 처리량(throughput)을 증대 시킨다. 한 클럭당 한개 데이터를 처리할 수 있을 때 최적의 성능을 보장할 수 있겠으나 항상 이를 만족하지 못하는 경우 데이터 흐름에 병목이 생겨 정체가 일어난다. HLS에 파이프라인 지시를 주는 위치에 따라 레이턴시와 인터벌 클럭수가 다른 것은 병렬 구조의 차이 때문이다.
예제는 3x3 크기의 행렬 곱셈기(matrix multiplier)다. 두 행렬은 함수 외부에서 2차원 배열로 주어지며 행렬곱은 2차원 배열로 출력된다. 입력과 출력의 2차원 배열이 RAM 메모리에 저장되었다고 하자. 함수 matrixmul()의 내용은 행렬 곱셈을 수행하는 3중 반복문으로 구성되었다.

[맨위로]
-----------------------------------------------------------------------------------------------------
단계 1. 병렬처리가 억제된 합성(최소 하드웨어)
HLS의 PIPELINE 지시자는 반복구문에서 변수들 사이의 의존성을 따져 병렬성을 파악하고 의존성이 있을 경우 파이프라인 구조를 만들어낸다. 이번 단계는 최소 하드웨워 자원을 사용하는 구조를 살펴보기 위해 행렬 곱셈기 함수에 PIPELINE을 억제 시키는 지시를 주고(PIPELINE off) 합성해 보자. 아울러 HLS가 다중 반복문을 어떻게 처리 하는지 스케쥴 뷰어를 통해 확인해 본다.

PIPELINE이 억제되어 합성되었으므로 3중 반복문이 그대로 존재한다. 각 반복문 별 레이턴시 계산해 보면 아래와 같다.
Product 라벨이 붙여진 가장 안쪽의 k-반복문 내의 실행문이 3회 반복(trip count)된다. 반복되는 실행문이 1개에 불과하나 복잡한 구성을 하고 있다. 메모리 a와 b에서 읽기, 그리고 res에 쓰기가 있으며 곱셈과 누적을 수행한다. 메모리에 접근하려면 2 클럭이 소요되는데 읽기 혹은 쓰기 전에 주소가 선행되어야 하기 때문이다. 1개의 실행문이 1클럭내에 실행될 수 없다. 합성된 하드웨어의 반복 레이턴시(iteration latency)가 7이며 3회 반복(trip)하므로 Product 라벨의 레이턴시는 15다.
Col 라벨 역시 3번 반복한다. 하위 Product 의 레이턴시 15에 반복의 시작과 끝을 확인하는 상태가 각각 추가되어 17이다. 따라서 Col의 레이턴시는 51이다.
최상위 Row 반복의 경우 한번 진행으로 끝나므로 재시작할 필요가 없이 종료 조건만 확인한다. 따라서 하위 Col 반복을 3회 진행하고 종료 확인을 목적으로 1개 상태(클럭)가 추가 되어 161 클럭의 레이턴시를 갖는다.

실제 HLS를 통해 수행된 스케쥴은 다음과 같다. k-반복내의 실행문에 병렬성이 있으나 병렬구조는 억제되었다. k와 j-반복은 재반복 되고 i-반복은 한 회로 끝나는스케쥴을 볼 수 있다.

RTL/HDL-SystemC Co-Simulation

[맨위로]
-----------------------------------------------------------------------------------------------------
단계 2. 최하위 반복에 파이프라인 지시

PIPELINE이 억제되어 합성되면 실행문에 병렬성이 있더라도 병렬구조로 만들어 내지 않는다. 비록 전체 병렬 구조가 배제되어 더라도 k-반복 내에 파이프라인 구조가 가능하다.

k-반복의 스케쥴 개념도는 아래와 같다. 입력 a와 b가 각각 별도의 메모리 블럭에 구현되어 있어서 동시 읽기가 가능하다. 단계1에서는 파이프라인을 허용하지 않았으므로 반복 인터벌 6을 k-반복에서 3회, j 반복에서 3회, i 반복을 3회하여 총 레이턴시가 162가 된다.

k-반복에 파이프라인을 허용한 하드웨어의 경우 ii=1이 가능하므로 인터벌 1을 가지고 k, i, j를 반복하여 레이턴시는 27이다.

스케쥴 뷰어로 확인해 보자.

만일 k-반복을 병렬처리 구조로 바꿀 경우 복수의 a 와 b를 동시에 읽어오는 상황이 생길 수 있다. 제한된 입출력 포트를 가진 RAM 메모리 자원은 동시에 다수 데이터를 읽고 쓰기가 불가능하므로 이런 병렬처리 요구가 불가하다. 따라서 반복을 시작하기 전에 순차적으로 RAM 접근을 진행해게 되어 ii가 1 이상을 넘는 바이얼레이션이 일어난다. 이를 제한된 자원으로 인한 ii-바이얼레이션(limited resource ii-violation) 이라 한다. 이에 대해서 다음 단계에서 다룬다.

RTL/HDL-SystemC CoSimulation 으로 확인해보면 다음과 같다. 파이프라인이 작동 되는 것을 알 수 있다.
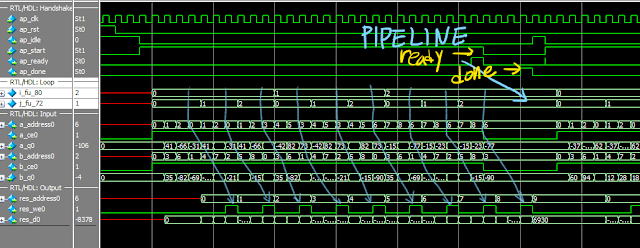
[맨위로]
----------------------------------------------------------------------------------------------------
단계3. 상위 반복에 파이프라인 지시
3중 반복 구문에서 j-반복에 PIPELINE 지시하면 하부에 놓인 k-반복은 병렬 구조로 풀어낸다.
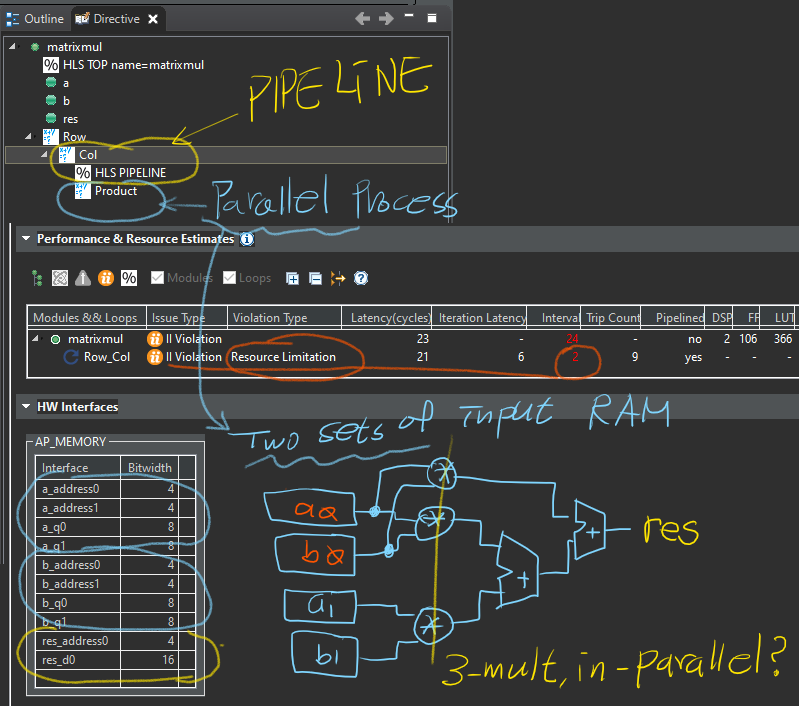
합성된 연사자들을 보면 3개의 곱셈기를 동원해 병렬 구조를 구성하고 있으나 RAM 메모리에 저장된 입력을 동시에 읽어올 수 없는 문제가 발생한다. 입력 a[]와 b[]는 병렬구조에 대응하기 위해 복제된 2쌍의 RAM에서 공급되는 구조다.

하지만 2쌍의 RAM으로 병렬구조의 곱셈기에 3-입력이 동시에 제공될 수 없어서 나누어 읽어와야 하므로 j- 반복을 시작하기 전에 두번째 a 값을 읽기위해 한 클럭을 더 소모하여 ii=2가 되어 바이얼레이션을 일으킨다.

PIPELINE 구조는 한 클럭 당 한개의 데이터 처리가 원칙이다. 반복을 시작하기 전 준비에 1 클럭 이상이 필요하면 ii 바이얼레이션이 발생한다. 바이얼레이션은 합성 실패가 아니다. 규칙에서 벗어났다는 의미다. 타이밍 바이얼레이션은 반드시 보완되어야 하지만 ii 바이얼레이션은 채택하기 여부에 달렸다.
RTL/HDL-SystemC CoSimulation

[맨위로]
-----------------------------------------------------------------------------------------------------
단계 4. 배열 재정렬(ARRAY_RESHAPE)
두 쌍의 메모리를 가지고 최하위 k- 반복에 병렬 구조를 구성했더라도 RAM의 동시 읽기가 불가하여 파이프라인 규칙을 따르는 것이 불가했다. 그렇다면 ii=2의 원인이 됐던 입력 배열 변수 a[] 를 병렬로 펼쳐놓자. 2차원 배열을 모두 펼치면 9개(MAT_A_ROWS*MAT_A_COLS) 입력이 될 것이다. 한번에 3 입력이 필요하므로 ARRAY_PARTITION=complete 대신 ARRAY_RESHPE 지시자를 적용한다. 배열 입력 a[]

스케쥴 뷰어, ii=1

RTL/HDL-SystemC CoSimulation
Row와 Col 라벨이 붙은 두 반복 문이 결합되었다. 합성보고에 나온 대로 반복 레이턴시(iteration latency)는 6, ii=1의 파이프라인이 9번 진행(trip count) 되어 함수의 동작이 종결됨을 알 수 있다.

배열 입력 a[]와 b[] 그리고 출력 res[]의 주소가 직렬(stream)이다. 입출력 인터페이스를 메모리 대신 FIFO 가 가능해 보인다. 시스템 설계에서 모듈간 인터페이스로 메모리 모다 FIFO 채널을 선호한다. 메모리의 경우 주소 생성과 읽기/쓰기 제어를 위해 클럭을 소모할 뿐 더러 데이터 패스 지연이 긴 편이다. 무었보다 FIFO 인터페이스 채널은 데이터 발생 갯수에 동기를 맞춰야 하는 부담이 적다. 위 예제에서 봤듯이 연산을 모두 끝내기 까지 a[]의 데이터 요구 횟수는 3번인 반면 b[] 는 9회에 이른다. 만일 FIFO 였다면 주소 생성에 번거로 움을 덜 수 있다. 제어 FSM의 상태수도 단순해 지고 그만큼 소요되는 하드웨어도 준다.
[맨위로]
----------------------------------------------------------------------------------------------------
단계 5. FIFO 인터페이스
입출력 인수 a, b 그리고 res에 FIFO 인터페이스 지시(INTERFACE=ap_fifo)를 주고 합성했다. 합성 결과 보고를 살펴보니 기대하는 효과를 얻지 못했고 ii 바이얼레이션을 냈다.

HLS 경고(Warning)를 살펴보자. 바이얼레이션은 실패(fail)가 아니므로 경고에 포함되어 있다.
WARNING: [HLS 200-880] The II Violation in module 'matrixmul' (loop 'Row_Col'): Unable to enforce a carried dependence constraint (II = 1, distance = 1, offset = 1) between fifo write operation ('res_write_ln65', matrixmul.cpp:65) on port 'res' (matrixmul.cpp:65) and fifo write operation ('res_write_ln61', matrixmul.cpp:61) on port 'res' (matrixmul.cpp:61).
소스 코드의 61번 줄과 65번 줄의 fifo 쓰기를 II=1로 불가함.
WARNING: [HLS 214-142] Implementing stream: may cause mismatch if read and write accesses are not in sequential order on port 'res' (matrixmul.cpp:54:0)
WARNING: [HLS 214-142] Implementing stream: may cause mismatch if read and write accesses are not in sequential order on port 'b' (matrixmul.cpp:54:0)
입력 b와 출력 res의 fifo 채널 인터페이스에 접근이 순차적이지 않음.(FIFO는 RAM 처럼 무작위 주소지정 할 수 없다.)
WARNING: [HLS 214-237] The INTERFACE pragma actions in object field. If on struct field, disaggregate pragma is required; If on array element, array_partition pragma is required. If no, this interface pragma will be viewed as invalid and ignored. In function 'matrixmul(char (*) [3], char (*) [3], short (*) [3])' (matrixmul.cpp:54:0) matrixmul_prj:
WARNING: [HLS 214-281] Estimating pipelined loop 'Col' (matrixmul.cpp:59:12) in function 'matrixmul' with estimated II increased from II=1 to II=2 because of limited port on variable 'res' (matrixmul.cpp:59:12) matrixmul_prj:
출력 포트 res 에 입출력의 동시 요구에 제한이 있으므로 ii=1 에서 ii=2 로 변경
WARNING: [HLS 207-5542] the expression for 'port' option is invalid, top argument that is ap_fifo/axis port may require the 'volatile' qualifier to prevent the compiler from altering array accesses and/or modifying the desired streaming order:
[맨위로]
----------------------------------------------------------------------------------------------------
단계 6. 함수 단위로 PIPLINE 지시
반복문 마다 세분하여 합성 지시를 주어 최적의 결과를 얻어내려면 상당한 노력이 든다. 때로는 함수 전체에 합성 지시를 내릴 수도 있다.

합성 결과표를 근거로 내부 구조를 추정해 보면 다음과 같다. k- 반복을 3개의 곱셈을 갖는 병렬 파이프라인 구조로 풀어내기 위해 입력 인수 a[]와 b[] 그리고 출력 res[]가 모두 2중 RAM 으로 구현 했다. 2중 i-반복(Row)과 j-반복(Col)은 9개의 3입력 병렬 곱셈기 구조로 펼쳐 놓은(flatten) 구조다.

스케쥴 뷰어를 보면 i, j, k 반복이 아예 없이 3중 반복문이 한데 뭉친 병렬처리 파이프라인 구조다. 클럭 성능을 최대한 끌어올리고 있으나 하드웨어 사용량이 매우 높다. HLS의 최우선 목표는 클럭 성능을 높이는 것임을 알 수 있다.

RTL/HDL-SystemC CoSimulation
RAM 메모리에서 한번씩 읽어들인 입력인수를 매우 영리하게 사용하여 3x3 행렬에 필요한 27번의 곱셈을 수행한다. 인수 a[] 와 b[]를 읽어들이는 순서(주소)에 주목해 보자. 그리고 한번씩 읽어들인 인수를 쉬프트 시켜 3병렬 곱셈을 9회 반복하는 연산을 10 클럭(레이턴시는 11)만에 완료하고 있다.


외부에서 제공되는 인수를 반복적으로 다시 읽지 않는 구조는 하드웨어의 모듈(라이브러리)화 측면에서도 매우 중요하다. 기능을 완료하기 까지 입출력 횟수를 줄여 자체 레이턴시를 줄일 뿐만 아니라 외부 모듈과의 의존성을 낮출 수 있기 때문이다. 시스템 설계에서 FIFO 채널 인터페이스를 추구하는 이유 이기도 하다.
그나저나 C의 반복문에서 병렬 구조를 끌어 낼 뿐만 아니라 입출력 인터페이스까지 고려해 스케쥴 까지 짜는 HLS의 최적화의 능력은 대단하다.
[맨위로]
-----------------------------------------------------------------------------------------------------
실습 2: 소스코드 변경
시스템에는 다양한 작동 모듈이 집적된다. 모듈간 입출력 데이터의 생성과 소모율이 다를 수 밖에 없다. 시스템의 통신을 관장하는 전역 컨트롤러(또는 스케줄러)는 매우 정교해야 한다. 구성이 다양할 수록 스케쥴러의 복잡성이 높아지고 집적(integration)하는 과정에서 하위 모듈의 변경 교체에 대응하기도 어렵다. 이럴 때 선택할 수 있는 방법이 다수 마스터를 허용(버스 스케줄러 scheduler, 아비터 arbiter 를 가진)하는 시스템 버스의 채택이다. 전송전 버스점유 허용 절차에 클럭 소모가 많아 소규모 입출력 혹은 클럭단위 입출력 모듈의 경우 불리하다. 버스트(스트림) 트랜잭션에 유리하다.
전역 스케줄러 없이 하위 모듈끼리 알아서 통신을 처리하는 방법으로 FIFO 인터페이스 채널이 있다. 모듈간 복잡한 핸드쉐이크가 필요 없다. 모듈은 통신 채널에 빈공간이 있는지, 읽어올 데이터가 쌓였는지 확인할 뿐 상대 모듈이 언재 통신할 준비가 되었는지 감시할 필요 없다. 시스템 관리자는 그저 구성 모들의 성능(쓰루풋, throughput)을 다그칠 뿐이다.
3x3 행렬 곱셈기를 ii=1인 파이프라인 구조에 입출력에 FIFO 인터페이스 채널로 합성해 보자. 앞서 단계 5에서 입출력 포트에 INTERFACE=ap_fifo 지시를 주었으나 성공하지 못했다. 함수 내 중복 반복문에서 포트를 무작위(random) 주소 접근으로 읽은 탓이다. 게다가 반복적으로 다시 읽기까지 하는 구조로는 fifo 인터페이스는 불가하므로 소스를 수정해 주기로 한다. 입출력을 미리 한번 읽어두는 방식으로 바꿔 놓고 k- 반복의 누산(accumulation)을 출력 포트에 누산시키지 않고 내부 임시 변수를 쓰도록 한다. FIFO 인터페이스의 요건에 맞도로 수정된 C 소스코드는 아래와 같다.

합성 결과 보고를 보면 인터페이스에 문제가 있어 보인다. 입력 b[] 와 출력 res[]는 FIFO 인테페이스로 합성되었으나 입력 a[]는 여전히 메모리 인터페이스다.
생성된 RTL/HDL을 가지고 SystemC CoSimulation 을 해보면 a[]의 주소도 순차적이며 다시 읽기도 없다. 메모리 인터페이스에서 FIFO로 변경되지 않은 이유는 알 수 없다. ARRAY_RESHAPE에 dim=2 로 한 것이 원인 것으로 보인다.

[맨위로]
고위 합성 튜토리얼(High-Level Synthesis Tutorial)
[목차][이전][다음]
댓글 없음:
댓글 쓰기