6장. 설계 분석-I (Design Analysis-I)
개요C 설계 검토 및 검증: 2차원 DCT(2-D Discrete Cosine Transform)
단계 1. 최초 합성
단계 2. 최상위 모듈에 파이프라인 지시(최고 클럭 성능)
단계 3. 최상위 모듈에 파이프라인 억제 지시(최소 하드웨어 자원)
-----------------------------------------------------------------------------------------------------
개요
C/C++ 설계로부터 고위합성(HLS)으로 RTL/HDL 구현의 수순의 일반적인 과정은 다음과 같다.
(1) 알고리즘을 기술한 C 언어 설계가 준비(검증) 되었다.
(2) C/C++ 설계를 합성한다.
(3) 최초 합성 결과 보고서를 보고 성능요구에 부합 하는지 검토한다.
최초 합성은 별도의 지시 없이 합성기의 자체 판단으로 합성된 것이다. 소프트웨어 개발시 컴파일러의 기본 옵션으로도 만족할 만한 결과를 얻기 쉽다. 작동개념이 전혀다른 하드웨어 합성의 경우 옵션(지시자)에 따라 매우 상이한 성능결과를 낳는다. 기본 옵션으로 요구 성능(소요 클럭수와 자원 사용량)을 맞추는 경우는 드물다.
(4) 요구 성능에 부합할 때 까지 적절한 최적화 지시자를 주고 합성과 검토를 반복한다.
가급적 원 설계(source code)를 손대지 않아야 한다. 온갖 합성 지시의 적용에도 요구성능을 맞추지 못한다면 별수 없이 설계를 수정한다. 설계 알고리즘을 다 알지 못하더라도 기본적인 구조는 파악해야 적재적소에 최적의 합성지시자를 줄 수 있다.
-----------------------------------------------------------------------------------------------------
C 설계 검토 및 검증: 2차원 DCT(2-D Discrete Cosine Transform)
이번 실습에 사용할 예제는 2차원 이산 코사인 변환(DCT)이다. 자료형은 모두 16비트 정수로 꾸며져 있다. 코사인 변환 알고리즘의 기본 특성은 계수 행렬 곱하기 입력 벡터다. 곱셈과 누적이 반복되는 계산구조다. 1차원 8 샘플 DCT를 그림으로 표현하면 아래와 같다.

코사인 계수 행렬의 의미를 이해해 보자. y[0] 는 입력 샘플 x[i]에서 코사인 계수행렬 첫번째 열의 특징을 갖는 성분의 크기가 된다. 즉 상수성분이다. y[1]은 코사인 계수행렬 두번째 열의 특징을 갖는 성분의 크기다. 즉 주파수가 1인 성분이다. 이어서 y[6]은 코사인 계수행렬 여섯번째 열의 특징을 갖는 성분의 크기다. 즉 주파수가 3인 성분의 크기다. 결국 DCT 변환을 마치고 y[i]를 살펴보면 입력 샘플 x[i]에서 어떤 변화성분을 가지는지 분석해 준다. 이런 삼각함수 변환은 시계열 샘플에서 변화특성 성분(혹은 주파수)을 찾아주는 알고리즘이다.
계수 행렬식을 보면 대칭성을 가지고 있다. 부호만 다르고 같은 계수값을 곱하게 된다. 곱셈을 굳이 여러번 수행 할 필요가 없다. 앞서 곱한 값을 나중에 더하고 빼기만 다시 활용해서 곱셈의 횟수를 줄일 수 있다. 소위 고속 알고리즘이라고 하는 것이다. 예제로 사용할 C 설계 dct()는 고속 알고리즘을 적용한 것은 아니며 쌩짜 행렬 곱셈이다.

[참고]
[1] 이산 코사인 변환, 위키백과
[2] Discrete Cosine Transform, Wikipedia
[3] 8-tap Winograd DCT oprimised for F-CPU
[4] Spectral Decomposition of Two-Dimensional Atmospheric Fields on Limited-Area Domains Using the Discrete Cosine Transform (DCT)
[5] Design and Implementation of a High-Performance and Complexity-Effective VLIW DSP for Multimedia Applications
[6] 2D DCT
------------------------------
여담: DCT 계산에 대해 잘 모른다고 겁먹을 것 없다. 가끔 수학이 약하다며 설계를 걱정하는 경우를 보게 되는데 본분을 망각한 소리다. 우리는 DSP 알고리즘을 고안해 내는 수학자가 아니라 이용자들이란 점을 잊지말자. 알고리즘을 발견하고 증명해 준 수학자들에게 감사하며 이용을 잘하면 된다. 사실 DSP에 관한 수학을 원리부터 증명까지 해내며 사용하는 경우를 본적이 없다. 우리가 언재 논리식 간략화부터 따지며 디지털 설계를 했던가 말이다. 그것이 뭔지 잘 이해하고 활용할 줄 알면 되는 거다. 물론 행렬 곱셈이 뭔진 알거라 믿는다.
------------------------------

2차원 입력 데이터에 대한 DCT는 dct_2d() 가 두번 실행되는데 그 사이에 행렬 트랜스포스(transpose)가 있다. 그리고 dct_2d() 내에 8번의 1차원 DCT 함수 dct_1d() 가 수행된다. 따라서 2D-DCT의 완료를 위해 총 16번의 1D-DCT가 수행된다.

2차원 DCT의 가장 핵심인 1D-DCT 함수 dct_1d()의 C 코드는 다음과 같다.

8회의 16비트 곱셈을 누적하면 최대 (32비트+4비트)까지 값을 갖는다. DESCALE()은 연속적인 곱셈과 누적으로 인한 오버플로우를 방지하기 위해 하위 비트를 잘라내는 매크로다.
2중 반복문이 포함된 dct_1d()의 하드웨어 합성 옵션
1차원 8x8 DCT의 알고리즘을 단순화 시켜보면 다음과 같다. 안쪽 반복문에 src[n] 와 C[k][n]을 곱해 dst[k]에 저장한다. 할당문 오른편과 왼편의 의존 관계를 따져 보면 k 반복은 양쪽에 동시성을 가진다. 이에 반해 n 반복은 할당문 왼편 내에서 누적 된다. 반복 누적은 파이프라인 으로 처리 된다.

파이프라인을 하지 않았을 경우 다음과 같은 하드웨어 구조 가졌을 것이다. 최소의 하드웨어 자원을 사용하지만 소요 클럭은 매우 많은 클럭을 소모한다.

안쪽 반복문에 파이프라인 합성하면 다음과 갖은 구조를 가지게 된다. 하드웨어 사용량은 급격히 늘어나지만 소요 클럭 수가 감소하여 고성능을 얻을 수 있다.

반복문 내 할당문 양쪽에 색인의 의존성이 없기 때문에 바깥쪽 반복문은 동시 처리가 가능하다. 클럭 소요가 매우 감소하지만 하드웨어 사용량은 급격히 증가한다. 게다가 64개의 src[64]도 동시에 준비되어야 한다. 동시 병렬 처리를 하려면 입출력도 그에 맞춰 준비되어야 한다.

C 설계 검증

-----------------------------------------------------------------------------------------------------
단계 1. 최초 합성 [소스 다운로드]
합성 목표로 지연 타이밍을 10ns 이내, 인터벌을 130 클럭 이내로 잡았다. 8x8 2D-DCT 알고리즘의 특징은 직렬로 입력되는 64개의 데이터를 메모리에서 읽고 쓰면서 동작한다. 메모리 주소생성에 1클럭, 읽기 및 쓰기에 1클럭을 잡더라도 최소 128클럭이 소요되는 알고리즘이다. 먼저 별도의 합성 지시 없이 합성해 본다.

지연 타이밍은 목표를 맞췄지만 인터벌은 430으로 목표치 130을 한참 넘었다. 다행히 기본 옵션으로도 DCT를 구성하는 모든 하위 함수들이 파이프라인 구조로 합성된 것으로 봐서 DCT 알고리즘이 기본적으로 고성능 파이프라인 구조로 합성 하는데 무리가 없어 보인다. 각 하위 함수들이 차지하는 인터벌 수도 골고루 분포하고 있다. 그도 그럴 것이 모든 하위 함수들의 특징이 2중 배열로 메모리 읽기와 쓰기를 반복 하고 있기 때문이다.

C의 반복문을 하드웨어로 변환할때 변수들 사이의 의존성을 따져 병렬성을 찾고 의존성을 갖는 경우 파이프라인 구조를 갖도록 합성한다. 다중 반복문이 포함된 경우 가장 안쪽의 반복을 먼저 파이프라인 처리한다. 합성 보고서를 보면 2중의 for 반복 중 안쪽 반복 문이 파이프라인 구조로 펼쳐졌고 바깥쪽 반복을 수행하도록 합성되었음을 알 수 있다.

최초 합성으로 얻은 RTL/HDL의 SystemC 테스트 벤치 Co-Simulation

레이턴시와 인터벌이 각각 429와 430이다. 입출력 메모리 주소가 직렬 순차적이다. 만일 레이턴시를 64 까지 줄일 수 있다면 전체 파이프라인 구조가 가능할지도 모른다.
---------------------------------------------------------------------
스케쥴 뷰어(Schedule Viewer)
스케쥴 뷰어(Schedule Viewer)는 HLS 가 C/C++ 설계를 RTL로 합성하면서 클럭 진행을 어떻게 했는지 보여준다. 아울러 합성 중 메모리 객체(RAM과 레지스터)들 사이의 의존관계 처리 그래프도 보여 준다. 합성기는 객체들 사이의 의존관계를 따져서 하드웨어의 병렬 혹은 순차(파이프라인) 구조를 결정하게 된다. 스케쥴 뷰어를 보면 dct()의 하위 함수들이 어떻게 실행 되었는지 알 수 있다. 최초 합성의 스케쥴을 보면 하위 함수들 내부에서 파이프라인 구조를 이루고 있으나 부분 모듈 사이의 병렬성을 전혀 고려되지 않았다.

dct()의 하위 함수 중 1차원 DCT를 처리하는 dct_1d()의 내부 스케쥴을 보면 다음과 같다. 아래 그림은 dct_1d()의 스케쥴 중 일부를 보여준다. DCT_Inner_Loop의 for-반복문에 8번의 곱셈이 있는 것을 4개씩 펼쳐서 병렬처리 하고 1클럭 간격으로 파이프라인 처리하는 구조로 합성 되었음을 보여준다. 스케쥴 뷰어는 해당 합성 그래프에 해당하는 C 코드의 대응을 보여준다(Goto Source). 설계분석에 매우 유용한 기능이다.

-----------------------------------------------------------------------------------------------------
단계 2. 최상위 모듈에 파이프라인 지시(최고 클럭 성능) [소스 다운로드]
INLINE 은 하위 함수(모듈)을 구분하지 않고 평평하게(flattening) 모으는 지시자다. 최상위 모듈에 PIPELINE을 지시하면 INLINE 하지 않더라도 하위 함수들을 모두 한데 모아서 파이프라인 구조로 합성한다. 하위 함수들이 한데 펼쳐 있으므로 합성기는 설계 전역에 걸쳐 병렬 및 파이프라인 구조를 찾아낸다.

합성 결과 보고를 보면 비록 II(Interval Initiation) 바이얼레이션이 있으나 인터벌이 겨우 32로 엄청나게 줄었고 레이턴시는 69다. 메모리에서 64개 데이터의 읽기와 쓰기를 수행 하려면 메모리 주소가 선행되어야 하는 절차를 감안 하면 매우 적은 수의 인터벌이다. 좀더 최적화를 지시하면 완전 파이프라인 처리가 가능할까? 파이프라인에 집착하는 이유는 시계열 샘플을 지체 없이 처리해 낼 수 있는 구조이기 때문이다.

스케쥴 뷰어를 보면 레이턴시의 0번째 클럭에서 69번째 클럭 까지 전과정이 파이프라인 처리되고 있음을 보여준다. 되돌림이 없도록 반복문을 모두 펼친 병렬 구조를 하고 있으므로 자원 공유(resource sharing)가 없기 때문에 하드웨어의 규모가 엄청나게 늘어났다.

---------------------------------------------------------
배열 변수: 레지스터(Register) vs 메모리(Memory)
배열 변수를 구현하는 방법은 메모리 혹은 레지스터다. 변수를 레지스터(프립플롭, F/F)로 구현하면 매우 빠른 하드웨어 구조를 만들 수 있지만 소요되는 회로의 양이 너무나 늘어난다. 메모리는 밀집된 회로구성이 가능하기 때문에 반도체 면적 차지가 적으면서 대규모 저장소 구성이 가능하다. 하지만 주소지정 후 읽기 또는 쓰기 동작을 해야 하므로 추가 클럭이 든다. 더블어 주소 생성규칙을 짜야하기 때문에 다소 복잡한 계산이 들어간다. 물론 이 계산은 합성기가 알아서 해준다.
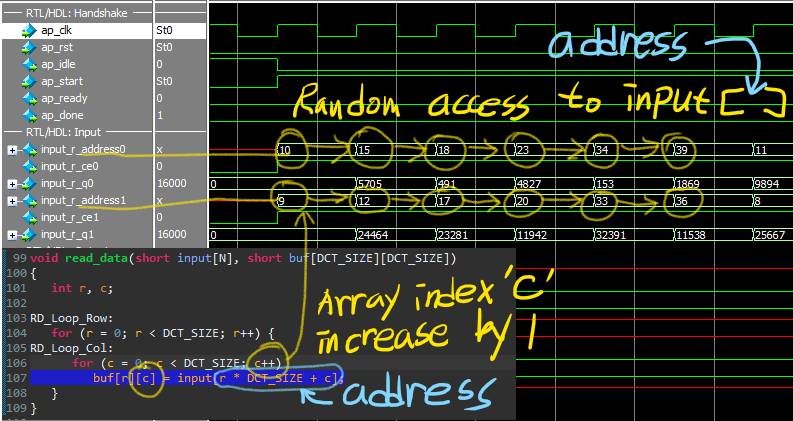
합성기는 프로그래밍 언어의 순차 반복문이더라도 읽고 쓰는 변수들 사이의 의존관계를 따져 병렬성을 찾아낸다. 따라서 하드웨어로 구현된 회로에서는 배열 변수의 주소가 마치 규칙성이 없어 보일 수 있다. 고위 합성된 dct()의 입출력에 메모리가 사용되었다. 이 메모리에서 읽거나 쓰는 순서(주소)가 무질서 한 듣 보이는데 이는 병렬 구조를 위해 계산된 주소다. 따라서 입출력 자료를 저장하는 메모리는 RAM(random access memory) 이어야 한다. 입출력에 저장소를 RAM 대신 FIFO 방식을 취하면 주소지정 단계가 없으므로 대용량이면서 빠른 하드웨어 구성이 가능 하다. 하지만 알고리즘마다 병렬성이 다르기 때문에 FIFO를 쓸 수 없는 경우에 해당한다.
------------------------------------------------------------
인터페이스에 두 세트의 메모리(RAM)를 둔 이유
DCT 알고리즘의 특성은 한 변수에서 두개의 데이터를 요구하는 두 연산의의 결과는 서로 의존 관계가 없다. 두 연산이 병렬성을 가진다고 한다. 반복문을 펼쳐 놓으면 동시에 실행 시켜도 좋다. 단, 입력 데이터 역시 동시에 준비 되어야 한다. 병렬성을 최대한 살리기 위해서 내용이 동일한 메모리를 두쌍을 두어 병렬 처리를 가능케 한다.

입력과 마찬가지 이유에서 함수의 출력에도 두 개의 메모리 인터페이스를 두고 있다. 입력의 경우 동일한 내용의 RAM을 두면 됐지만 출력은 두 내용을 합쳐 주어야 한다.

------------------------------------------------------------
Loop Pipeline Initiation Interval(II)
처음 입력이 주어지고 출력이 나오기 시작 할 때 까지 인터벌은 32, 동작이 완전히 종료할 때까지 레이턴시는 69다. 이 둘의 차이가 크다고 해서 문제 될 것은 없다. 다만 출력이 개시 되면서 새로운 시작이 가능할 때 파이프라인 처리의 장점이 있다. 2D-DCT 알고리즘의 경우 출력이 순차적으로 나오지 않기 때문에 출력이 나오기 시작하는 시점인 ap_ready에서 새로운 입력을 줄 수 없다. 모든 출력이 완료되는 ap_done 될 때까지 ap_start를 기다려야 한다. 이는 파이프라인 처리를 해치기 때문에 초기 인터벌 조건을 위배했다는 경고를 냈다. 입출력에 FIFO 인터페이스를 쓸 수 없었던 이유와 같다. 애써 많은 하드웨어 자원을 동원하여 고속의 구조(인터벌이 짧은)를 만들었지만 레이턴시가 그의 두배에 달한다면 낭비라 할 것이다.

파이프라인 처리를 목표로 했다면 합성하기 전부터 II 바이얼레이션을 미리 예측하고 원시 코드를 수정할 수 있어야 한다. 하지만 알고리즘의 개발단계에서 모든 병렬성을 따져가며 알고리즘을 기술하기는 쉽지 않다.
[참고]
[1] Loop Pipeline Initiation Interval Estimation Using LLVM
HLS 가 내는 II 바이얼레이션 메시지는 합성에 실패 했다는 뜻이 아니다. 파이프라인 처리 규칙을 위배 했다는 일종의 경고다. 이 사실을 인지 했으므로 합성 지시자에 PIPELINE II=32 라는 추가 옵션을 주면 바이얼레이션은 사라진다. 합성 보고서에서 빨간 경고는 없으면 좋은 것이다.

------------------------------------------------------------
하드웨어 사용이 과도하지만 고속의 합성 결과를 받아 들일 것인가?
반도체 성능은 하드웨어 규모와 클럭 소요량의 두가지 측면에서 따진다. FPGA는 이미 하드웨어가 모두 배치되어 생산된 반도체 부품이다. FPGA가 허용하는 용량에 설계가 들어간다면 클럭 소요량만을 따져 결정 할 수 있다. 어짜피 제조된 FPGA 용량을 굳이 남길 이유는 없다. FPGA가 계산 가속화(computing acceleration)를 목적으로 활용되는 경우 빠른 처리속도 위주의 결정을 한다. 더구나 필요에 따라 용도를 바꿀 수 있는 재구성 가능한(reconfigurable) FPGA를 HLS와 함께 활용 한다면 마치 소프트웨어를 실행 하는 CPU 처럼 사용될 수 있다. ASIC 제조전 검증용으로 많이 사용되는 대규모 FPGA는 고성능 계산기(high-performance computing machine)로도 여러 산업 분야에서 널리 활용되고 있다. 취약한 환경의 산업분야(우주항공 aerospace, 방산 defense, 의료 medical, 원격측정 telemetry 등)에서 고속 CPU는 클럭의 주기 간격이 너무 좁기 때문에 위험하다. 낮은 클럭 속도의 계산기이면서 고속 처리를 요구하는 경우 재구성 가능한 FPGA의 활용도는 높다.
[0] FPGA Research
[1] South Pole Telescope Software Systems: Control, Monitoring, and Data Acquisition
[2] Accelerating Scientific Computations using FPGAs
[3] The Advantages of Embedded FPGA for Aerospace and Defense
[4] What are the applications of FPGA in the aerospace field
-----------------------------------------------------------
파이프라인 처리를 하려 했으나 입출력의 무작위 주소 툭성 때문에 어짜피 파이프라인 처리가 불가해졌다. 굳이 과도한 하드웨어를 써가며 파이프라인으로 합성할 이유가 없다. 클럭 소요 목표치인 130 클럭 이내로 줄여 과도한 하드웨어 사용을 줄이는 방안을 찾아보자.
댓글 없음:
댓글 쓰기