6장. 설계 분석-II (Design Analysis-II)
개요C 설계 검토 및 검증: 2차원 DCT(2-D Discrete Cosine Transform)
단계 1. 최초 합성
단계 2. 최상위 모듈에 파이프라인 지시(최고 클럭 성능)
단계 3. 최상위 모듈에 파이프라인 억제 지시(최소 하드웨어 자원)
-----------------------------------------------------------------------------------------------------

단계 3. 최상위 모듈에 파이프라인 억제 지시(최소 하드웨어 자원) [소스 다운로드]
C 설계 함수 dct()를 구성하는 하위함수들에 기본으로 들어갔던 파이프라인 지시를 억제 시켜 놓고 합성해 보자. 하드웨어를 최소로 쓰는 구조가 될 것이다.

설계 전반에 걸쳐 2중 for 반복문이 있고 안쪽 반복(inner Loop)에서 자원 공유된 탓에 소요된 하드웨어 자원의 양이 최소화 되었으나 인터벌이 너무 커서 고속처리를 원했던 목적에 한참 뒤진다.

시뮬레이션으로 확인 해보면 한개 입출력 읽기와 쓰기에 3클럭을 쓰고있다. 특히 출력 쓰기 타이밍을 보면 8번째 마다 쓰기에 한 클럭이 더 소요되는데 반복문 탈출 검사가 필요 했기 때문이다. 확실히 파이프라인 처리는 전혀 하지 않고 있음을 알 수 있다.

굳이 스케쥴 뷰어(schedule viewer)를 보면서 확인 할 필요는 없겠지만 '실습'이니 만큼 반복문이 어떻게 합성되는지 보기나 하자. 메모리에 출력 데이터를 써넣는 부분의 스케쥴이다. 원 소스에 레이블을 붙여 놓으면 분석할 때 도움이 된다. 특히 반복문에 레이블이 붙이도록 하자.
스케쥴 표를 보고 있노라면 합성기가 상당히 잘 처리하고 있는 것을 볼 수 있다. 마치 C에서 변환된 어셈블리(assembly)어를 보는 느낌이다. 스케쥴 뷰어에서 녹색으로 표시된 화살표(green arc)은 되돌림 반복이다. 파이프라인 구조를 위해서 녹색 그래프를 없애야 한다. 스케쥴 표를 보면 역방향 그래프는 모두 2중 for 반복문에서 안쪽 반복에 걸려 있다.
-----------------------------------------------------------------------------------------------------
단계 4. 반복문 최적화: 파이프라인 지시 [소스 다운로드]
수많은 합성 지시를 줄 수 있다. 일일이 다 적용해보기도 좋지만 시간이 오래 걸릴 뿐더러 합성 지시가 기대와 정반대 결과를 내기도 한다. 따라서 지시를 주고 결과 분석 과정을 통해 최적의 합성 결과를 얻기 위해 전략적으로 접근해 보자. 이번 단계는 반복문에 파이프라인 합성 지시를 하고 그 결과를 분석해 보자. 반복문이 중첩되어 있다면 안쪽 반복문을 먼저 파리프라인 처리를 지시하는것이 일반적인 접근이다. 단계 1의 최초 합성은 dct()를 구성하는 하위 함수의 2중 반복 중 안쪽 반복에 모두 PIPELINE 을 적용하고 얻은 결과다.
4-1. 입출력 데이터 처리 함수 read_data()와 write_data()에 PIPELINE 지시

다중반복(nested loop)이 있는 경우 가장 안쪽 반복에 PIPELINE 을 적용하는 전략이 항상 좋은 결과를 낳는 것은 아니다. 먼저 데이터 입력 부분부터 병렬성을 높여 보기로 하자. read_data()는 dct() 전과정에서 파이프라인의 시작점이기도 하다.
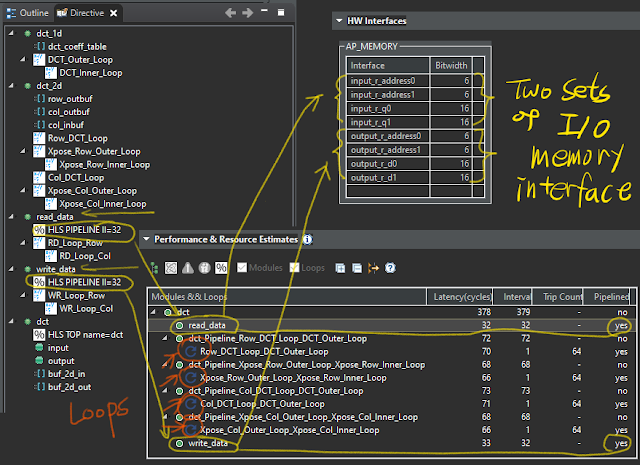
read_data() 와 write_data()의 외측 반복에 준 PIPELINE 지시자가 효과가 있었다. 레이블 앞에 있던 반복 표시(둥근 화살표)가 모두 사라졌고 부분 레이턴시도 반으로 줄었다. 병렬성을 높이려고 입출력 메모리 인터페이스가 두쌍이 된 점에 유의하자.
4-2. 1차원 DCT dct_1d()에 PIPELINE 지시
가장 많은 연산과 반복이 포함된 함수는 1차원 DCT, dct_1d() 다. 특히 이 함수는 2차원 DCT 를 위해 8행에 대한 처리를 두번 실행되고 양쪽으로 2차원 메모리 트랜스포스를 두고 있다. 따라서 2차원 DCT 내에는 총 16번의 1차원 DCT가 실행 된다.

메모리 트랜스포스는 알고리즘의 특성상 앞의 1D-DCT 가 완료되기 전까지 시작할 수 없다. 단독으로 파이프라인 처리가 불가하다.

PIPELINE 지시를 dct_1d() 함수에 주는 위치에 따라 합성 결과가 달라진다. 병렬처리 구조 변경을 함수 내부에 제한하거나 연결된 외부 함수까지 영향을 미칠 수 있다. 클럭 성능이 향상되면 높은 병렬 성을 추구하는 구조가 되어 하드웨어 자원 사용량은 증가한다.
(1) dct_1d() 내의 외곽 반복 DCT_Outer_Loop에 PIPELINE 를 지시한 경우:
dct_1d()는 레이턴시 16을 갖는 파이프라인 처리되지만 8행 반복 Row_DCT_Loop 와 Col_DCT_Loop 가 파이프라인에서 제외되어 전체 레이턴시 552로 성능이 오히려 악화됨. 파이프라인에서 제외된 반복에서 사용하는 배열변수는 레지스터 메모리 대신 BRAM을 활용 한다.

(2) dct_1d() 전체에 PIPELINE 를 지시한 경우:
dct_1d()가 레이턴시 16을 갖는 파이프라인, 이 함수와 연관된 8행 반복 Row_DCT_Loop 와 Col_DCT_Loop 가 파이프라인 구조를 갖진 못했으나 dct_1d()와 결합되어 전체 레이턴시 176으로 향상됨. 하드웨어 자원 사용량 3배가량 대폭 증가함. 모든 배열 변수들이 레지스터 변수로 구현 되었기 때문에 BRAM 사용은 없다.

(3) dct_1d()함수와 외곽 반복 DCT_Outer_Loop에 PIPELINE 을 동시에 지시한 경우:
dct_1d()의 내부 최적화와 외부 8행 반복을 분리 합성 함. dct_1d()의 내부 레이턴시 7, 외부 8행 반복 Row_DCT_Loop 와 Col_DCT_Loop 가 레이턴시 1로 8번 반복함. 전체 레이턴시 265. 레이턴시와 하드웨어 사용량의 타협이 이뤄짐. 배열 변수 일부가 BRAM으로 구현 되었다.

4-3. 메모리 트랜스포스 반복에 PIPELINE 지시
dct_1d()에 준 PIPELINE 이 클럭 성능 면에서 효과가 있었으므로 이를 선택하고 양쪽에 끼고있는 트랜스포스의 외곽 반복에 같은 합성 지시를 주었지만 좋은 결과를 얻지 못했다. 합성 결과를 보면 전체 레이턴시가 176에서 272로 올라 갔고 하드웨어 사용량은 오히려 증가했다. 앞서 이뤄진 1차원 DCT의 8행 반복 이후 트랜스포스 메모리 사이에 병목이 있다는 바이얼레이션이다.

메모리 병목을 해결하기 위해 dct_1d()와 트랜스포스 사이의 2차원 배열을 분할(array partition)해 주어 바이얼레이션이 해결했다.

최종적으로 얻은 dct()의 레이턴시가 138 목표치 130보다 조금 크다. 최초 합성(단계1)에 비해 레이턴시는 430에서 138로 줄었고 하드웨어 사용량은 6배가량 증가 했다.
고성능 합성(단계2)의 레이턴시 69에 비해 두배지만 하드웨어 사용량은 1/4 수준이다. 클럭 성능과 하드웨어 사용량 사이의 적당한 타협이다.
각 단계에서 사용된 배열 변수들의 구현 방식에 주목해야 한다. 파이프라인 처리가 강화 될 수록 대규모 배열 변수에 BRAM 대신 LUT 내의 플립플롭으로 구현되어 하드웨어 사용량이 급격히 증가한다. FPGA 처럼 미리 배치된 경우라면 어짜피 있는 자원 그대로 활용할 테지만 ASIC 이라면 심각히 고려되어야 한다. HLS 합성 옵션(지시자)에 따라 레이턴시와 하드웨어 사용량 변화폭이 상당 함에도 FPGA에서 이를 검토대상에 넣고 받아들이는 이유는 미리 배치된 반도체 부품이기 때문이다. ASIC 을 목표로 한다면 저장소에 RAM/ROM을 활용 할지 플립플롭으로 구현할지 명확히 해주므로 옵션 변화에 따른 성능차는 작다. 대용량 FPGA를 목표로 하는 HLS의 경우 하드웨어 자원 활용을 최대한 허용하므로 상대적으로 합성이 수월한 편이라고 할 것이다.
-----------------------------------------------------------------------------------------------------
단계 5. 병렬성 강화 최적화(DATAFLOW) [소스 다운로드]
앞선 단계까지 dct_2d()를 구성하는 하위 함수들에 대하여 최적의 PIPELINE 합성을 찾았다. 최종적으로 얻은 dct()의 구성은 read_data(), write_data() 그리고 dct_2d() 다. 세 하부 블럭들을 묶어 병렬 실행성(parallelism)을 찾아 보기 위해 DATAFLOW 지시자를 적용해 보자.

인터벌이 139에서 72로 줄었다. dct()를 구성하는 세 하위 모듈들의 인터벌을 모두 더한 것보다 적다. 전체 인터벌과 가장 많은 클럭을 쓰는 dct_2d 모듈의 인터벌이 같다. 세 모듈들이 병렬로 실행되게 되었다는 뜻이다.
만일 dct_1d의 출력 버퍼와 트랜스포스 메모리를 합쳤더라면 메모리 자원을 절약하고 트랜스포스 동작이 아예 없어져서 소요 클럭도 줄일 수 있었을 것이다. 하지만 한 메모리에 대한 열 쓰기(column read)와 행 읽기(row write)를 동시에 하기는 불가하므로 하위 구성 모듈간 병렬 처리는 없다. 따라서 병렬처리로 얻은 인터벌 72 대신 32+71+32=135 에서 두번의 트랜스포스 처리에 소요된 16(=8+8, 외곽 반복 횟수)을 뺀 인터벌은 119 다.

하위 모듈 병렬처리를 RTL/HDL-SystemC Co-Simulation으로 확인해 보자. 최초 레이턴시 137 클럭 이후 read_data와 write_data 모듈이 dct_2d와 병렬 처리되면서 인터벌이 72로 반복된다. 2차원 데이터는 입력 버퍼 buf_2d_in[][]와 출력 버퍼 buf_2d_out[][] 그리고 트랜스포스 col_in_buf[][]의 3단계에서 저장된다. 따라서 병렬 처리 후 출력 데이타는 읽기와 3단 차이를 두고 반복된다는 점도 유의하자. 최초 레이턴시 입력에 대한 출력 후 인터벌 출력 사이의 출력은 무효한 출력이 있다.

입출력 메모리 RAM의 주소도 가지런 해졌다.

-----------------------------------------------------------------------------------------------------
단계 6. 계층구조 최적화(INLINE)
계층 구조화(hierarchy)는 소프트웨어 개발에서 함수를 라이브러리화 하여 재사용성을 높여 코드 메모리의 절약을 위한 기법이 될 수 있지만 하드웨어에서는 의미없다. 인터벌을 가장 많이 차지하는 dct_2d() 를 dct()의 하위 모듈에서 끌어 올려 평탄화 시켜 보자. 하위 모듈을 반복적으로 호출 하느라 소요되는 클럭을 줄일 수 있다.

주: 인터벌이 32로 줄긴 했으나 이는 어디까지나 병렬 처리하는 하위 모듈 중 가장 긴 인터벌을 차지하는 숫자일 뿐, 실용성 없는 숫자다. 32 클럭 내에 하위 모듈들의 병렬 실행 스케쥴을 잡기도 어려울 뿐만 아니라 입출력 메모리를 읽기에도 빠듣하다. 32클럭마다 계속 읽어온다면 외부에서 입출력 데이터를 저장해줄 틈이 없다. 이럴때 메모리 입출력 대신 FIFO를 쓰는 것이다.
고위 합성 튜토리얼(High-Level Synthesis Tutorial)
[목차][이전][다음]
댓글 없음:
댓글 쓰기